

La grande illusione dei Big Data. Gli algoritmi comprendono davvero il mondo?
18 min letturaNel 2009 l’azienda telefonica Nokia era ancora leader di mercato nei paesi emergenti come la Cina. Aveva investito molto nei Big Data e aveva deciso che il suo modello di business sarebbe stato quello di produrre smartphone di fascia alta, per l’élite. L’etnografa Tricia Wang, invece, condusse una ricerca sul campo, e suggerì di concentrarsi non su una minoranza selezionata, ma su un pubblico più vasto: gli utenti a basso reddito secondo lei sarebbero stati disposti a pagare per smartphone più costosi (era l’epoca degli Shanzai phone). I dirigenti della Nokia rigettarono le conclusioni di Wang, sostenendo che il suo campione di 100 persone era “debole” rispetto all’immensa quantità di dati di cui disponeva l’azienda: nessuno degli indicatori quantitativi dei Big Data supportava la sua teoria.
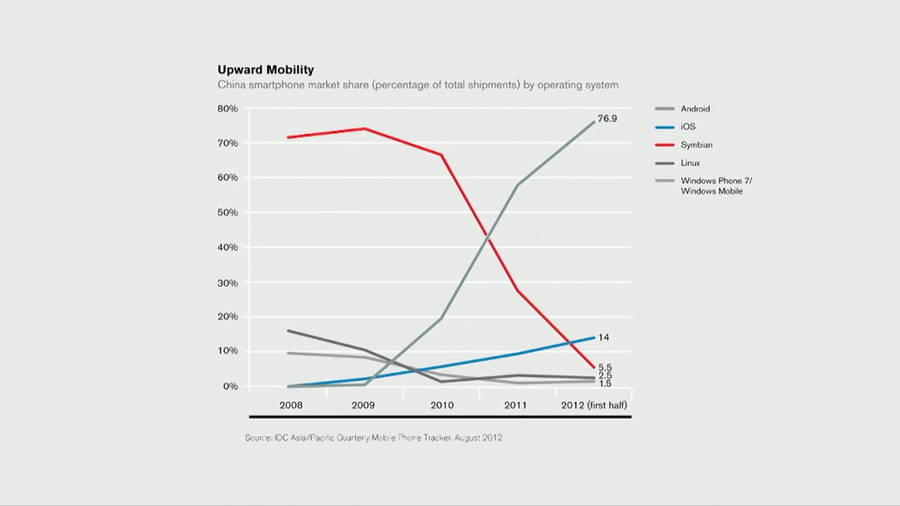
Il modello di sviluppo di Nokia fu un disastro. Nel 2013 l’azienda fu assorbita dalla Microsoft e la sua quota di mercato oggi si è ridotta fino allo 0,7%.
L’era dei Big Data
Fino a qualche anno fa la parola d’ordine era Big Data, ogni conferenza che parlasse di tecnologia doveva avere un panel sui Big Data. Oggi si parla per lo più di algoritmi o intelligenza artificiale, ma sono sempre i Big Data la base sulla quale queste tecnologie si poggiano. Gli entusiastici libri sui Big Data e gli algoritmi ormai si sprecano, favoleggiando della rivoluzione tecnologica che risolverà i problemi della società, la rivoluzione dei Big Data e degli algoritmi è qui tra noi, adesso, potente e irreversibile.
L’idea comune degli algoritmi è che siano in grado di trovare modelli complessi nei flussi di dati e generare previsioni (previsioni!) in tempo reale, gli algoritmi imparano e si adattano automaticamente. Insomma, gli algoritmi sono quella tecnologia che convertirà enormi flussi di dati informi in valore per tutti. Esperti di marketing e uomini d'affari sbavano sui Big Data. Dati sulle persone, le loro attività, i loro bisogni, le loro speranze, le loro emozioni, dati da Facebook, Twitter, Instagram, Google, Apple, molti giocherellano coi Big Data, moltissimi producono contenuti che alimentano i Big Data. Siamo seduti su petabyte di dati e tanti, troppi, vanno in giro chiedendosi cosa possono farci con tutti quei dati.
In effetti, mentre i database hanno masticato dati per oltre un secolo, Internet ha creato delle opportunità senza precedenti di produrre, aggregare, organizzare, condividere e diffondere dati, oggi i dati sono l'aria digitale che respiriamo. Alcuni problemi si prestano davvero a soluzioni di Big Data, ad esempio l'industria ha fatto enormi passi avanti nel riconoscimento vocale, e il bosone di Higgs non sarebbe mai stato scoperto senza di essi.
Chris Anderson è stato uno dei primi ad abbracciare il nuovo mantra. Le aziende una volta dovevano fidarsi di modelli poco affidabili, oggi non devono nemmeno più accontentarsi dei modelli. I computer hanno reso leggibili le informazioni, Internet le ha rese raggiungibili, i motori di ricerca ne hanno fatto un unico database e organizzate in maniera utile.
Il mondo degli affari e la scienza si concentrano sempre di più su questi enormi dataset, ritenendo che una quantità enorme di dati è indice di neutralità e autorevolezza. Del resto, sostiene Anderson, Google ha conquistato il mondo della pubblicità con nient'altro che matematica applicata, non ha mai preteso di sapere qualcosa della pubblicità, ha solo presunto che dati migliori lo avrebbero portato a vincere la sfida. E ha avuto ragione. Analogamente Google Translate non conosce realmente le lingue, eppure riesce a tradurre senza problemi centinaia di lingue. Allora perché non applicare la medesima procedura anche alle scienze, alla chimica, alla biologia, perfino alla medicina. Insomma, la correlazione è più che sufficiente? Tutto quello che serve è avere più dati?
I Big Data sono diventati la soluzione a prescindere, ma sono anche un ottimo investimento. Coi Big Data non hai mai torto, se il tuo algoritmo non offre la giusta soluzione puoi sempre dire che è il sistema del cliente che ha un problema, che i dati non sono buoni, che c’è troppo rumore in essi, che semplicemente sono troppo pochi.
La grande illusione
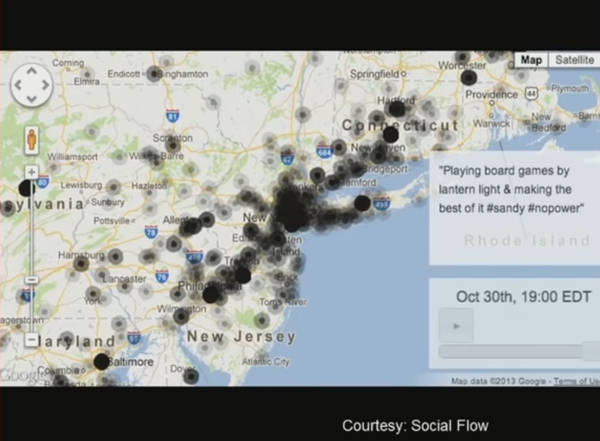
Nel 2012 l'uragano Sandy colpisce la Giamaica, Cuba, Bahamas, Haiti, la Repubblica Dominicana e la costa orientale degli Stati Uniti, raggiungendo la zona a sud della Regione dei Grandi Laghi degli Stati Uniti e il Canada orientale, con venti fino a 185 km/h. Secondo uno studio sui dati tratti da Twitter e Foursquare il picco della spesa si è avuto, prevedibilmente, la notte prima della tempesta, ma la vita notturna inspiegabilmente sarebbe ripresa il giorno dopo. In realtà, i dati vengono principalmente da Manhattan dando l’illusione che fosse il centro del disastro, mentre ben pochi messaggi venivano dalle zone più colpite: Breezy Point, Coney Island e Rockaway. Ancora meno dalle zone gravemente colpite, a causa dei blackout della rete elettrica e cellulare. Si presume che i dati riflettano il mondo sociale, ma nella realtà riflettono solo quella parte privilegiata che ha avuto meno danni e si è ripresa più velocemente.
I Big Data di Google Flu Trends, tool online ritenuto affidabile e in grado di mappare l’influenza stagionale, nel 2013 evidenziano una sopravvalutazione (11% invece del 6% stimato dal CDC), probabilmente dovuto alla copertura mediatica della stagione influenzale che causa un picco nelle query di ricerca. Ciò che Google osserva non è il fenomeno in sé quanto piuttosto l’interpretazione del fenomeno da parte dei suoi osservatori, gli utenti.
Siamo in un’era nella quale i dispositivi personali si sostituiscono agli individui e diventano i reali oggetti dell’osservazione (proxy) da parte delle aziende e dei governi, ma siamo anche in un’era nella quale chiedersi “perché” non ha più alcun senso, ciò che conta davvero è solo il “cosa”. Non importa spiegare la causa di un fenomeno, ciò che rileva è stabilire una correlazione tra eventi, una qualsiasi.
Le tecnologie di sorveglianza estraggono dati dai dispositivi, dati che vengono smontati e rimontati a discrezione (dei programmatori, in base alle specifiche esigenze di chi “sorveglia”), a scomporre l’individuo in una serie di flussi che verranno poi ricomposti nei silos di dati per essere riassemblati in modo da servire l’agenda istituzionale. Si chiama “datificazione” (We Are Data: Algorithms and the Making of Our Digital Selves, John Cheney-Lippold). “Dato” viene dal latino “datum”, participio passato neutro del verbo dare, e differisce da “fatto”, ciò che è accaduto o esiste. Un fatto è tale finché è vero, se dimostrato falso cessa di essere un fatto, un dato no, è sempre un dato, anche se falso. Il dato, quindi, è una creatura effimera e corruttibile, che può perdere anche il proprio significato, o assumerne uno del tutto differente ("Raw Data" Is an Oxymoron, a cura di Lisa Gitelman).
I dati non sono altro che una costruzione umana mediata dagli algoritmi, i dati sono creati dai software programmati dagli ingegneri, non sono qualcosa di preesistente osservabile, gli algoritmi non osservano né sorvegliano, tutto ciò che fanno è interpretare gli output dei device digitali e matematizzarli. In questo modo abbiamo trasformato il sociale e il naturale in qualcosa che sia gestibile da un algoritmo creato dall’uomo. E, essendo creato dall’uomo, come tale l’algoritmo soffre di tutti i pregiudizi di cui soffre anche il suo creatore.
Dal 2017 in alcune scuole a Hong Kong si utilizza un’intelligenza artificiale per analizzare le espressioni facciali dei bambini. L’idea alla base di “4 little trees” ha le sue radici negli studi di Paul Ekman (che sono anche alla base del programma del governo americano per l’identificazione dei terroristi), in base ai quali esisterebbero 6 emozioni universali, innate e interculturali, che possono essere lette attraverso le espressioni facciali. Ma, secondo l'antropologa Margaret Mead e gli studi più recenti in materia, questa teoria non ha un reale fondamento, perché non tiene conto del contesto, della cultura e dei fattori sociali. Questa teoria è screditata anche dagli psicologi, ma è comunque utilizzata a Hong Kong (da 83 scuole) ed è ben vista anche al di fuori di Hong Kong. Allora perché la si utilizza comunque? Secondo Kate Crawford, fondatrice dell’AI Now Institute di New York, perché si adatta bene a ciò che i sistemi di AI possono fare, cioè è facilmente gestibile da un software. In questo modo le emozioni sono ridotte, semplificate, standardizzate e matematizzate. Basta semplicemente ignorare tutto ciò che fuoriesce dagli schemi, che non è leggibile dagli algoritmi.
Cosa manca ai Big Data?
I Big Data sono una lente potente e liberatoria per poter osservare il nostro mondo, e possono essere particolarmente utili in sistemi che sono coerenti nel tempo, con proprietà semplici e ben caratterizzate, poche variazioni imprevedibili e una complessità sottostante relativamente ridotta. Ma non importa quanto siano grandi quei Big Data, è solo un’istantanea, un momento nel tempo. Analizzando i Big Data abbiamo l’impressione di vedere l’intero mondo con estrema chiarezza, ma è solo un’illusione. Secondo Kate Crawford i Big Data soffrono di una serie di problemi.
1. Bias: i dataset sono pieni di pregiudizi, occorre verificare da dove vengono i dati e quale è il contesto perché essi abbiano un valore, insomma occorre conoscerne il significato.
2. Rappresentanza (signal): nella rappresentazione dei Big Data mancano sempre delle categorie, facciamo delle scelte ogni volta che decidiamo di usare dei dati.
3. Scala: nell’enorme quantità dei dati i fenomeni piccoli non emergono, ma quei fenomeni sono esseri umani come tutti gli altri.
Più dati non vuol dire che i dati siano migliori, anzi spesso è il contrario, nella furia di accumulare dati su dati si tende a inserire di tutto, talvolta senza una reale significatività. Le compagnie di assicurazione forniscono polizze in base ai Big Data, fissano il premio in base ad una serie di fattori: dati demografici, indirizzo fisico, reclami passati, violazioni, credit score. Spesso ciò che manca è proprio l’elemento più importante, il comportamento di guida. Tutti gli altri dati sono solo rumore nel dataset, e possono facilmente portare a discriminazioni (perché chi guida bene dovrebbe essere penalizzato solo perché vive in un certo quartiere?), ma i dati “telematici” si cominciano ad utilizzare solo adesso, perché è costoso raccoglierli, a differenza di tutti gli altri dati. Si usa ciò che si ha a disposizione, anche se in realtà non serve allo scopo.
Gli ingegneri sostengono la validità del loro campione, solo perché è costituito da milioni di dati. Ma grandezza del campione non significa completezza, se disponi di milioni di tweet devi considerare ciò che Twitter rimuove, devi valutare che non tutti twittano con la stessa frequenza (alcuni utenti sono sovracampionati), alla fine tutto ciò che hai è solo un campione casuale di tweet pubblici. C’è un’arrogante convinzione che i Big Data siano completi, puri, neutrali, ritenendo che i dati estratti dai social siano più accurati di quelli utilizzati dai sociologi. I dati non sono generici solo perché “modellabili”, devi capirne il significato, devi sapere esattamente cosa stai misurando, altrimenti cadrai facilmente in errore. Solo perché utilizzi dati quantitativi non vuol dire che non li stai interpretando, è sempre un’interpretazione dei dati. E se non conosci i tuoi pregiudizi e i tuoi limiti, la tua interpretazione dei Big Data sarà sbagliata, non importa quanto sono grandi i tuoi Big Data.
E tutto questo senza menzionare le questioni etiche, solo perché i dati sono accessibili non significa che utilizzarli sia etico. La matematizzazione delle persone, la loro trasformazione in numeri ha reso più facile giustificare le intrusioni nelle nostre vite private, in qualsiasi condizione e momento, e per qualsiasi scopo.
Nessuno ama i Big Data più dei marketer, e nessuno li interpreta peggio, perché i venditori credono che “cosa” risponda alla domanda “perché”. In questo inebriamento da Big Data ben pochi si fermano giusto il tempo per chiedersi cosa significano davvero quei dati. Puoi avere anche tutti i dati di questo mondo, ma alla fine se non parli davvero con le persone non saprai mai perché fanno quello che fanno.
I dati qualitativi
Alcuni sistemi sono facilmente quantificabili, come le reti elettriche o il genoma umano, ma altri sistemi, specialmente se dinamici, sono più difficilmente quantificabili, in particolare tutto ciò che riguarda la sfera umana, sistemi complessi che si modificano nel tempo, certe volte lentamente, certe volte in pochissimo tempo.
Quando un’azienda completa il nuovo e fiammante silos di Big Data, una flotta di data scientist li analizza per estrarre le risposte “definitive”. Ma le informazioni estraibili dai dataset sono soggette alle legge dei rendimenti decrescenti. Parlare di Big Data innesca aspettative di accelerazione dei rendimenti, se ho un dataset grande il doppio mi aspetto il doppio dei risultati, e così via. Ma non funziona così, una decuplicazione dei dati spesso dà solo un incremento minimo dei risultati. Bruce Upbin su Forbes offre questo esempio. La prima immagine è in bassa risoluzione, la seconda in alta risoluzione (x10), eppure la seconda immagine non da più informazioni rispetto alla prima. Invece la terza immagine, a colori, ci da informazioni del tutto nuove.

Non sempre è utile moltiplicare la quantità di informazioni, spesso è più utile concentrarsi sulla diversità dei dati disponibili.
I dataset sono un fermo immagine di un momento specifico, abbracciano diversi anni o anche meno, e anche se aggiungiamo nuovi dati sono quelli storici che assumono maggiore importanza (il nucleo del profilo virtuale). Ma gli esseri umani evolvono, e anche piuttosto velocemente. Non possiamo ignorare i dati di lunga durata, altrimenti otteniamo dei sistemi tesi a replicare il passato, che ci dicono che evolversi, crescere, maturare, è qualcosa che va fuori scala, qualcosa di anomalo e quindi da rigettare, qualcosa di “sospetto”. La “normalità” finirebbe per essere l’assenza di cambiamenti. Per comprendere bene i dati occorre collocarli in un contesto storico di lungo periodo.
Netflix nasce nel 1997 con un modello di business concentrato sulla vendita e il noleggio di DVD. Nel 2002 dichiarava perdite per 57 milioni e si apprestava ad essere acquisita dal rivale Blockbuster (fallito poi nel 2013). Progressivamente introduce il video on-demand e nel 2007 passa allo streaming di film e serie tv. Gran parte del successo di Netflix si basa sugli algoritmi di raccomandazione e gli studi relativi agli utenti. Netflix ha influenzato il modo in cui il pubblico guarda i contenuti televisivi, poiché Internet consente ad ogni utente di guardare secondo il proprio ritmo, un episodio non ha necessità di cliffhanger per stuzzicare il pubblico. Le reti tradizionali non sono disposte a rischiare milioni di dollari in spettacoli senza prima vedere un episodio pilota, ma Netflix si basa sui dati che estrae dagli utenti, e decide cosa può avere successo e cosa no, in questo modo si eliminano gli episodi pilota con un notevole risparmio di costi.
Netflix ha sempre usato dati quantitativi (Big Data) che rivelano informazioni preziose sugli spettacoli e le preferenze degli spettatori, ma dicono poco sul comportamento dello spettatore, su come si sente quando guarda uno spettacolo. Per questo decide di aggiungere nuovi dati, i dati qualitativi (Thick Data o dati “spessi”, dati “profondi”) in base alle intuizioni fornite dall'antropologo culturale Grant McCraken. Così Netflix ha iniziato a fornire intere stagioni di episodi tutti insieme, piuttosto che rilasciare un episodio alla settimana. In questo modo Netflix ha capitalizzato la consapevolezza che i suoi abbonati preferiscono il “binge watching” di più episodi di una serie in un breve lasso di tempo. Netflix dà maggiore libertà e controllo ai propri utenti, una scelta vincente secondo le statistiche di Nielsen.
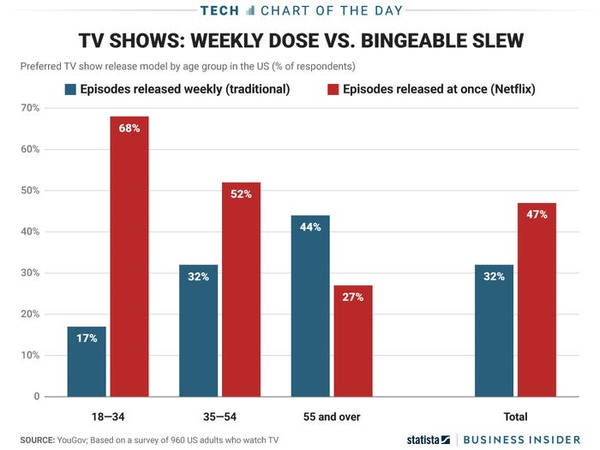
I Big Data ci dicono dove e quando gli utenti utilizzano un certo prodotto, ma sono i Thick Data che rivelano le storie umane dietro il consumo del prodotto, sono i dati “spessi” che rispondono alle domande più complesse: cosa fa quel prodotto ai suoi utenti, cosa significa per loro?
L’approccio dell’antropologo (o dell’etnografo come Tricia Wang) coglie gli elementi di complessità di una situazione registrando la prospettiva interna, ciò che viene osservato non è interpretato ma descritto analiticamente, non ci si preoccupa di trovare le prove per spiegare il rapporto causa-effetto (spesso sbagliando perché assurgono la correlazione a causa) quanto di capire cosa succede in un certo contesto. L'approccio dell'antropologo fornisce, quindi, una prospettiva diversa, più profonda, in grado di arricchire il quadro e di validarne l’interpretazione. Insomma, è in grado di andare oltre l’illusione algoritmica.
Con interviste strutturate otteniamo il “perché” di un comportamento che dà il vero senso al “quanti” che ci fornisce il dato quantitativo (i Big Data), le scienze sociali portano consapevolezza al contesto, e sono quelle che davvero ci consentono di affrontare i seri problemi di “rappresentanza”. Nel mucchio dei dati è facile perdersi le minoranze, i discriminati. I Thick Data sono il contrappeso ai Big Data per mitigarne i problemi, ma il problema è che sono costosi, molto più costosi dei dati quantitativi. Ecco perché spesso non vengono utilizzati sostenendo che “basta avere più dati” (quantitativi ovviamente). Alla fine è sempre un problema di incentivo economico.
La maggior parte dei problemi sociali sono tutt’ora irrisolti anche se la rivoluzione dei Big Data è qui da tempo, è solo un’illusione credere che i Big Data stiano aiutando, in realtà spesso non fanno altro che alimentare le discriminazioni umane su larga scala. I Big Data sono un potente strumento per dedurre le correlazioni ma non certo un modo per capire la causalità.

“Quanti” vs “Perché”
Chris Anderson nel 2008 diceva che i numeri parlano da sé, che non occorre altro. Ma in realtà i numeri non parlano da sé, siamo noi che gli diamo voce, siamo noi che li estraiamo, li classifichiamo, gli diamo un significato e un’interpretazione. I dati sono sempre una costruzione, e come tali soffrono sempre di bias e di problemi. E questo è un serio problema se basiamo sui Big Data le decisioni aziendali, oppure la spesa pubblica.
Per avere il quadro reale di cosa accade nel mondo i Big Data non bastano, e stiamo cominciando a capirlo, occorre rispondere alla domanda “perché”, non solo a quella “quanti”. Se ci accontentiamo di sapere “quanti” fanno una determinata cosa e sfruttare questo “dato” per finalità economiche, o anche di altro tipo, tutto ciò che otteniamo è oggettivizzare l’intera popolazione, in una sorta di determinismo tecnologico che alla lunga può portare i governi a vedere i cittadini più come semplici numeri piuttosto che persone reali. Se invece vogliamo risolvere seriamente i problemi della società non possiamo esimerci dal conoscere quei cittadini a fondo, conoscere i loro problemi reali. Ci occorre qualcosa di più che solo le scienze sociali possono darci.
Integrare i Big Data coi Thick Data non è solo una questione di intrattenimento o pubblicità, ma talvolta anche di vita o di morte. Intorno al 2012 gli Stati Uniti avevano attivo il progetto Skynet (documenti pubblicati nel 2015), un progetto di sorveglianza di massa tramite la rete di telefonia mobile del Pakistan, con un algoritmo di intelligenza artificiale per valutare la probabilità di 55 milioni di cittadini di essere un terrorista. Gli elementi tenuti in conto erano principalmente gli schemi di viaggio (locazioni visitate, frequenza), e l’analisi dei comportamenti (uso di cellulari, solo in ricezione, molte SIM, lo spegnimento di un telefono cellulare ritenuto tentativo di eludere la sorveglianza di massa, ecc...).

We kill people based on metadata (Michael Hayden, ex direttore NSA e CIA)
Secondo Patrick Ball, direttore della ricerca presso lo Human Rights Data Analysis Group, i metodi dell’NSA vanno da “ridicolamente ottimisti” a “vere stronzate”, in sintesi scientificamente infondati. Dal 2004 al 2012 circa ci sono state tra le 2500 e le 4000 persone uccise in attacchi di droni in Pakistan, in base alla classificazione di “estremisti”. Migliaia di persone innocenti potrebbero essere state erroneamente etichettate come terroristi dall’algoritmo di Skynet. In base all’algoritmo venne etichettato anche il capo dell'ufficio di Islamabad di Al Jazeera, Ahmad Zaidan, come appartenente ad Al Qaeda. Perché? Perché si recava spesso in regioni con note attività terroristiche per riportare le notizie.
Leggi anche >> Rischi e problemi nella lotta al terrorismo nell’era degli algoritmi
Il problema, secondo Ball, è che esistono pochi terroristi conosciuti, per poter estrarre delle informazioni che siano in grado di costruire un modello attendibile di “terrorista”, per questo vengono utilizzati dati che non hanno reale attinenza con l’essere un terrorista. Come disse il premio nobel per l’economia, Daniel Kahneman ("Pensieri lenti e veloci") noi esseri umani cerchiamo una causalità anche lì dove non c’è, respingiamo l’idea che un processo sia davvero casuale, e siamo pronti a vederne una dovunque, siamo pronti a cercare e a trovare schemi dappertutto, più attenti al contenuti di un messaggio che alle informazioni sulla sua attendibilità. E, purtroppo, gli stessi schemi mentali che ci governano sono utilizzati per programmare gli algoritmi.
Leggi anche >> Il potere degli algoritmi sulle nostre vite
Esperimenti sociali
Il ventesimo secolo è stato funestato dagli agghiaccianti esperimenti sociali dei regimi che puntavano al controllo totale dei propri cittadini fino alla regolamentazione della vita interiore, cercando di conoscerli a fondo, anticipando le loro aspirazioni, sfruttando le loro paure.
Nell’ecosistema digitale odierno le aziende (e gli Stati che si servono di esse, o quali complici o in base a minacce “legali”) monopolizzano, frammentano e sorvegliano lo spazio di discussione pubblico. Una forma di controllo che sfocia nella vera e propria sorveglianza digitale, un fenomeno in costante diffusione: per riaprire in sicurezza dopo la pandemia, per regolamentare il flusso dei migranti e controllare i confini europei, per contrastare il terrorismo e la propaganda terroristica, o più banalmente per ragioni di efficienza economica. In tutto il mondo serpeggia una crescente paura per le “nuove” minacce, si fa strada l’idea che leggi più severe e controlli maggiori siano la soluzione, anche se ciò implica maggiori restrizioni per le libertà fondamentali. Così si moltiplicano i database che raccolgono i nostri profili virtuali, con una crescente centralizzazione e interconnessione dei vari silos. Non abbiamo imparato nulla dal passato quando, ad esempio, abbiamo superato l’emergenza terrorismo rimanendo fedeli alla Costituzione, dimostrando che alcune libertà e diritti valgono più di qualsiasi emergenza.
Questa forma di controllo finisce per essere non solo una “sorveglianza”, ma sempre più un indottrinamento, perché organizzano il nostro sapere, moderando e censurando (sempre più spesso richiesti in tal senso dagli Stati) quello che leggiamo e assorbiamo, plasmando le nostre scelte e la nostra visione del mondo. L’ecosistema digitale non è più un ambiente di conoscenza (spesso censurata con la scusa del copyright) quanto un luogo di inserimento di dati, il cui scopo è il consumo piuttosto che la comprensione critica per una crescita sociale, consumo di prodotti e servizi, consumo di idee, indignazione, slogan e programmi politici, che durano lo spazio di una pubblicità. Le nuove censure non stanno più nel silenziare le persone, quanto piuttosto nell’inondare lo spazio di discussione pubblica di messaggi di ordine opposto.
Il tecnosciovinismo moderno (Artificial Unintelligence, How Computers Misunderstand the World, di Meredith Broussard) ci vede come niente altro che degli automi, programmabili e prevedibili, alla merce dei marketer che producono algoritmi e li presentano, a scatola chiusa, quali soluzioni a tutti i problemi, anzi, come soluzioni in cerca di un problema. Ma se siamo solo degli automi programmabili, allora ci sarà sempre qualcuno che proverà a programmarci, ci sarà sempre un'élite di “esperti” che preparerà modelli previsionali nei quali vorranno inquadrarci a forza.
A quel punto della democrazia non sarà rimasto nemmeno più un barlume, lasciando sul campo solo l’assenza di politica (già perfettamente visibile dietro le maschere dei politici moderni) della fredda tecnocrazia (Hannah Arendt, Sulla violenza) non educata a discutere pubblicamente le questioni cruciali, ma più propensa a rispondere ai pochi che ai molti. Perché prestare attenzione alla volontà dei cittadini, ai loro bisogni, se questi possono essere anticipati e addirittura programmati? Perché fare un popolo libero se la libertà è sospetta? Perché considerarci essere umani se è più semplice ritenerci niente più che la somma di numeri? E, se non siamo nemmeno umani, perché mai dovrebbero preoccuparsi della nostra sofferenza?
Rispetto al secolo scorso abbiamo la presunzione di essere più evoluti, migliori, eppure oltre un milione di Uiguri nei campi di “rieducazione” cinesi sono lì a testimoniare il contrario. Per la prima volta nella storia dell’uomo abbiamo creato una generazione di cittadini datificati fin dalla nascita. Non è solo un problema cinese, ma è un fenomeno che si sta intensificando anche nei cosiddetti paesi “democratici”, man mano che questi comprendono che le esigenze di sicurezza sono più facilmente perseguite in un sistema centralizzato (alla cinese appunto). Il modello di sorveglianza cinese più che un qualcosa da combattere appare sempre più un qualcosa a cui aspirare. Da cui le pressioni sulle grandi aziende del web perché, grazie ai loro Big Data, fungano da sceriffi dello spazio virtuale, perché con la scusa del controllo della pedopornografia, del copyright e del terrorismo, censurino il dissenso, le voci contrarie e quelle che si discostano dalla massa datificata, cioè tutti i “mostri” della tecnologia. Così accade in India, in Nigeria, in Russia, ma con la piena automazione del processo (Jillian C. York, Silicon Values, The Future of Free Speech under Surveillance Capitalism) gradualmente si diffonde anche nella più “democratica” Europa.
Gli esperimenti sociali del secolo scorso sono tutti irrimediabilmente falliti perché, come asseriva Kant, gli esseri umani sono fatti di “legno storto”. Non siamo fatti per essere inquadrati in rigide scatole o precisi piani sociali, ci ribelliamo, e il fallimento degli esperimenti sociali si manifesta sempre in una violenza oscena. Un regime che non riesce a ridurre le innumerevoli moltitudini di individualità nelle stringenti categorie gestibili dagli algoritmi non avrà altra scelta che ricorrere alla violenza, psicologica, poi fisica, fino all’uccisione dei propri cittadini (Isaiah Berlin, Il legno storto dell’umanità). Il prezzo pagato per quegli esperimenti sociali è stato elevatissimo.
Il capo supremo deve essere giusto per se stesso e tuttavia essere un uomo. questo problema è quindi il più difficile di tutti e una soluzione perfetta di esso è impossibile: da un legno storto, come quello di cui l’uomo è fatto, non può uscire nulla di interamente diritto. Solo l’approssimazione a questa idea ci è imposta dalla natura (Immanuel Kant, “Idee zu einer allgemainen Geshicte in weltburgerlicher Absicht” (1784), “Idee di una storia universale dal punto di vista cosmopolitico”)
Articoli correlati
I nostri dati: il petrolio dell’economia digitale
Paura, controllo, sorveglianza digitale: benvenuti nell’era della società pre-crimine
Rischi e problemi nella lotta al terrorismo nell’era degli algoritmi
Algoritmi, intelligenza artificiale, profilazione dei dati: cosa rischiamo davvero come cittadini?
Il capitalismo della sorveglianza
Il potere degli algoritmi sulle nostre vite
L’algoritmo che prevede chi commetterà un crimine, tra poca trasparenza e pregiudizi
Gli algoritmi e i “mostri” della tecnologia
Immagine in anteprima via Pxhere.com




