

La raccolta dei nostri dati come forma di controllo sociale. Ecco perché è fondamentale la regolamentazione
11 min lettura- Ciao Mario, hai visto la mail che ti ho mandato?
- Ciao amore, si, vista. Anzi stavo appunto cercando su Internet. Volo più hotel, per cinque notti. Sarà una vacanza da sogno.
- Si, anche io stavo vedendo...
- Ecco, sono in tutto….
- 1.100 euro….
- 1.100…. cosa? No…… aspetta….
- Che c’è?
- Non sono 1.100, guarda meglio, sono 1.160.
- Aspetta, stesso volo, stesso hotel, stessa camera, stessi servizi, a me viene 1.100!
- A me 1.160.
(insieme) Ma come è possibile?
Con la piena applicazione del regolamento europeo per la protezione dei dati personali, nonostante ben due anni concessi per mettersi in regola, tantissimi si sono trovati impreparati. Molte critiche sono state sollevate da più parti, non solo dalle grandi multinazionali, che in verità più che altro hanno fatto lobbying, ma anche dalle piccole e medie imprese.
Molte sono le difficoltà avanzate, ma in particolare ci si focalizza sulle nuove e più stringenti regole, che impongono obblighi specialmente in relazione all’uso di strumenti di terze parti. Ad esempio, l’uso di banner dei circuiti pubblicitari, ma anche il semplice uso dei plugin social.
Si tratta di strumenti che impongono l’obbligo di bloccare i relativi cookie e chiedere un consenso preventivo agli utenti. In verità questo tipo di obbligo risale già alla direttiva precedente, e in particolare alla cosiddetta “cookie law”, insieme di norme che furono modificate proprio per regolamentare tali attività.
Le lamentele sono più o meno standard, del tipo che la normativa rende senz’altro più difficile utilizzare i banner pubblicitari anche solo per racimolare qualche migliaio di euro l’anno. E questo nonostante alcuni circuiti pubblicitari (ad esempio Google) abbiano messo a disposizione pagine esplicative e anche strumenti per la conformità con le norme.
C’è, quindi, una certa resistenza all’attuazione del cosiddetto GDPR. Mentre le grandi piattaforme si stanno mettendo in regola, date anche le elevatissime sanzioni, molte piccole imprese sembrano intenzionate a non farlo, o comunque farlo solo parzialmente. Non è raro, navigando online, trovare siti che presentano la sola “informativa cookie”, dimenticando che l’informativa prevista dall’art. 13 del GDPR (ma in realtà già dalla precedente direttiva) è l’informativa privacy della quale l’informativa cookie è solo una piccola parte. Si tratta di una violazione delle norme che può costare fino a 20 milioni di euro (art. 83 GDPR), anche se ovviamente le autorità di controllo nazionali (il Garante) dovranno rendere tali sanzioni proporzionate con l'attività.
Il punto è che al GDPR, talvolta senza nemmeno conoscerlo o fidandosi di un sentito dire, oppure semplicemente perché non lo si capisce e proprio per questo se ne diffida, si attribuiscono una serie di torti inesistenti, o comunque fortemente sovradimensionati. E molti si approcciano al GDPR come se fosse l’ennesimo formalismo burocratico da risolvere con l’informativa da “copiare” e che crea solo altri fastidi.
Una regolamentazione necessaria
La realtà è ben diversa. Il GDPR è una normativa ormai indifferibile. Così come un tempo ci si accorse della necessità di una regolamentazione per la guida degli autoveicoli, e per l'introduzione delle patenti (la prima risale al 1883, in Francia, con l’obbligo di non superare i 16 km/h), considerato il numero elevato delle auto in circolazione da un certo momento in poi e quindi la pericolosità della situazione, oggi una normativa che regolamenta in maniera più stringente un’attività pericolosa come quella del trattamento dei dati personali altrui è necessaria.
Perché negli ultimi anni, e in particolare dal 1995, epoca della precedente direttiva, si sono moltiplicati non solo nel numero ma anche nell’intensità i trattamenti di dati personali. Questi trattamenti hanno una capacità di entrare nella sfera personale degli individui, violandola, che ormai non è più pensabile che possa essere lasciata senza regole. E non stiamo parlando del semplice banner (che comunque raccoglie una notevole quantità di dati di coloro che navigano il sito) inserito da un piccolo gestore per racimolare pochi euro, né dei plugin social (il classico Like di Facebook per capirci) che anche sono pesantemente invasivi nella privacy delle persone, ma di vera e propria profilazione degli utenti.
Ed è inutile, oggi, andare a rinvangare polemiche di qualche anno fa, quando anche noi sostenemmo che forse un modo migliore per tutelare le persone non era tanto porre a carico del gestore di un piccolo sito obblighi relativi a tali strumenti, quanto piuttosto intervenire a monte con obblighi specifici di non tracciamento (ad esempio per i soggetti non iscritti ad un social network o non loggati che comunque navigano un sito con i social plugin) a carico dei social network, o comunque dei soggetti che effettivamente mettono a disposizione tali strumenti di tracciamento (es. Google, Facebook, Twitter, ecc….). Questo tempo è passato, le scelte del mercato ormai sono fatte e non pare vi sia intenzione di intervenire in tal senso (cioè vietando i tracciamenti da parte di terze parti), anche perché su tali strumenti si basa anche parte dell’economia digitale, il Digital Single Market.
Ma questo non vuol dire che tale attività non vada regolamentata in maniera più stringente, e che gli obblighi vadano a cascata a partire da chi prepara gli strumenti fino a chi li usa inserendoli nel proprio sito.
Perché il problema è l'invasività di tali servizi. Sempre più aziende realizzano procedure di profilazione degli utenti, sfruttando i gestori di piccoli siti (nel vero senso della parola, perché tali siti non solo non vedono nemmeno i dati ma alla fine ci ricavano ben poco dall’uso di tali strumenti), e realizzando profitti enormi. Basti vedere la capitalizzazione in borsa delle grandi piattaforme del web americane.
Ma non dobbiamo dimenticare che non si tratta delle sole grandi piattaforme del web, i nomi altisonanti che siamo abituati a conoscere perché usiamo i loro servizi quotidianamente, ma anche dei giornali, degli editori veri e propri, visto che anche loro utilizzano la profilazione (è profilazione anche se non si conosce il nome e cognome di una persona!) delle persone per veicolare pubblicità personalizzata.
Soprattutto, si tratta della raccolta di dati dei cosiddetti Data Broker, soggetti che stando dietro le quinte raccolgono i dati da mille rivoli diversi, stringendo partnership con moltissimi soggetti online e offline, al fine di realizzare profili degli individui che poi vengono usati da altre aziende per fornire servizi. E i servizi sono, appunto, quelli che consentono di proporre una copertura assicurativa ad un prezzo per Mario e per lo stesso identico rischio a prezzo diverso per Giovanni, quelle che consentono di proporre lo stesso identico pacchetto vacanze a due prezzi diversi nello stesso momento a due persone diverse, come nell'esempio in testa all’articolo.
Online i prezzi non sono più unici, ma dinamici, variano per diversi motivi, perché in quel momento quel prodotto o servizio è più ricercato, ma anche in relazione a chi sta chiedendo il servizio. Per chi ha una sinistrosità più elevata, ma anche solo se ha l’abitudine di guidare in maniera più “aggressiva”, come risulta dai dati del suo veicolo, dai sensori del suo smartphone, in grado di tracciare dati quali l'accelerazione, oppure dalle scatole nere che si stanno diffondendo con le polizze, ci sarà un prezzo di assicurazione più elevato. È difficile dire perché i prezzi variano da persona a persona, può dipendere da tanti fattori, come il fatto di aver cercato quel servizio più volte (vuol dire che è più interessato), oppure per altri motivi che non è dato sapere. Motivi che dipendono dall’algoritmo.
I cosiddetti Big Data consentono, tramite analisi inferenziali, di personalizzare i prezzi in tempo reale ("Big data e prezzi personalizzati" di Mariateresa Maggiolino). Si tratta di una discriminazione che la società non è ancora abituata a comprendere, o comunque della quale le persone non sono ancora consapevoli. Quello che una volta faceva il venditore di auto usate, cioè cercare di indovinare il prezzo massimo che una persona è disposta a pagare in base al reddito, ai gusti e a una miriade di altri dati, raccolti da un enorme insieme di fonti, è quello che probabilmente cercano di fare gli algoritmi che usano le aziende online. Ma l'algoritmo, a differenza del venditore, ha a disposizione una miriade di informazioni raccolte da ogni dove. Può essere positivo, pensiamo a servizi offerti in sconto ad anziani o bambini, ma molto probabilmente il risultato è che tali servizi siano offerti al prezzo massimo a chi ne ha più bisogno, che non ne può fare a meno.
Come si inserisce in tutto ciò il GDPR?
La nuova normativa in materia di protezione dei dati personali, si concentra su una serie di principi che fanno la differenza rispetto alla precedente direttiva. In particolare si focalizza sulla trasparenza e quella che viene definita accountability.
Accountability non è solo responsabilità, ma è un doverne rendere conto, nel senso che il titolare del trattamento deve rendere conto di ciò che fa con i dati degli interessati, i suoi utenti, i suoi clienti. L’accountability si deve concretizzare nell'adozione di una serie di comportamenti proattivi a dimostrazione della concreta e non meramente formale adozione del regolamento europeo. Ciò vuol dire che non esistono più adempimenti formali, meramente burocratici, da adottare, che ti mettono in regola. Essere in regola vuol dire, infatti, decidere in autonomia le modalità e i limiti del trattamenti dei dati alla luce dei principi specifici indicati nel regolamento. Quindi, non è più la legge che indica cosa fare, né il Garante, è il titolare che lo stabilisce in base alla propria specifica realtà, così consentendo il regolamento anche una flessibilità e adattabilità all’azienda che la precedente direttiva non aveva.
L’approccio del GDPR è basato sul rischio, inteso come la misura della responsabilità del titolare, tenendo conto della natura, della portata, del contesto e delle finalità del trattamento, nonché della probabilità e della gravità dei rischi per i diritti e le libertà degli utenti. Un approccio di tal fatta pretende, quindi, obblighi che vanno ben oltre la mera conformità alla legge, ed è più flessibile, e tiene in maggiore considerazione le esigenze delle aziende stesse, rendendo meno burocratica la gestione del dati. Aziende più piccole, infatti, avranno minori obblighi, essendo questi parametrati anche all'organizzazione della stessa.
Altro principio essenziale è quello della trasparenza. L’informazione agli utenti-interessati è essenziale, proprio a dimostrazione della corretta implementazione del regolamento. La trasparenza non è solo un principio fondamentale del trattamento, ma un vero e proprio diritto dell’interessato. Devono essere trasparenti le modalità di raccolta dei dati, le modalità di utilizzo, deve essere trasparente la base giuridica del trattamento, la finalità dello stesso, e tutto questo ben prima che si inizi il trattamento. Gli interessati devono essere in grado di capire cosa accade ai loro dati, quali dati vengono raccolti, come vengono trattati, per quale motivo e soprattutto, a chi tali dati possono essere passati (comunicati, diffusi).
In tale ottica, il GDPR mira a combattere i cosiddetti trattamenti occulti, o comunque poco trasparenti. Cioè tutti quei trattamenti dove la raccolta viene fatta senza un’indicazione chiara di quali dati vengono raccolti e a chi vengono comunicati. Si tratta, a bene vedere, proprio del caso dal quale siamo partiti, cioè del trattamento realizzato tramite i cosiddetti cookie, ma anche i pixel gif di Facebook, i web beacon di MailChimp, gli AdID, gli identificatori univoci su dispositivi mobile (IDFA per IOs e AAID per Android), tutte tecnologie di tracciamento che consentono la raccolta di una quantità enorme di dati degli utenti, tramite i gestori di piccole realtà aziendali oppure semplici siti. Mentre questi gestori si lamentano del fatto che loro “i dati non li vedono nemmeno”, che non è giusto che “debbano rispondere di trattamenti altrui”, tramite i loro siti una enorme massa di dati viene raccolta e passata alle grandi aziende del web e ai loro innumerevoli partner.
Ecco, i partner. Una delle aziende che più si è prodigata sulla trasparenza, mettendo a disposizione dei suoi “clienti” (cioè quelli che usano i suoi servizi, come Analytics, AdSense, ecc…) è Google. Google mette a disposizione la possibilità di utilizzare annunci personalizzati ma anche non personalizzati (cioè l’annuncio viene pubblicato lo stesso ma non in base al profilo dell’utente). Nel primo caso occorre anche scegliere l’elenco dei fornitori. All’apposita pagina di amministrazione di AdSense, Google specifica che “in base alle norme relative al consenso degli utenti dell'UE, è necessario identificare ogni fornitore di tecnologia pubblicitaria che riceve dati personali degli utenti finali in seguito all'uso di un prodotto Google e fornire informazioni sull'uso di tali dati. I fornitori di tecnologia pubblicitaria (tra cui Google, altre reti pubblicitarie e altri fornitori) utilizzano i dati sui tuoi utenti, ad esempio, per mostrare annunci personalizzati o fornire informazioni sulle conversioni”. Si tratta di 658 fornitori.
Quindi, i dati che le grandi piattaforme, gli editori, i data broker e gli innumerevoli circuiti pubblicitari ricevono dai siti, anche il piccolo sito delle ricette della nonna che presenta, però, due plugin sociali e un banner per recuperare i pochi euro l’anno del costo dell’hosting (occorre dire, però, che molti di questi servizi possono essere configurati in modo da essere meno invasivi), passano per le mani di centinaia di aziende, e non è nemmeno esattamente chiaro cosa ci facciano. Ci viene detto che li usano per inviare pubblicità personalizzata. Ma, personalizzata in base a cosa esattamente?
Il GDPR mira non certo a impedire di fare business, quanto piuttosto a portare alla luce questo tipo di trattamenti poco trasparenti. Fino ad oggi ben pochi erano consapevoli di questa enorme massa di dati che transitano per i server di così tante aziende. molte anche sconosciute. Così i data broker profilano gli individui.
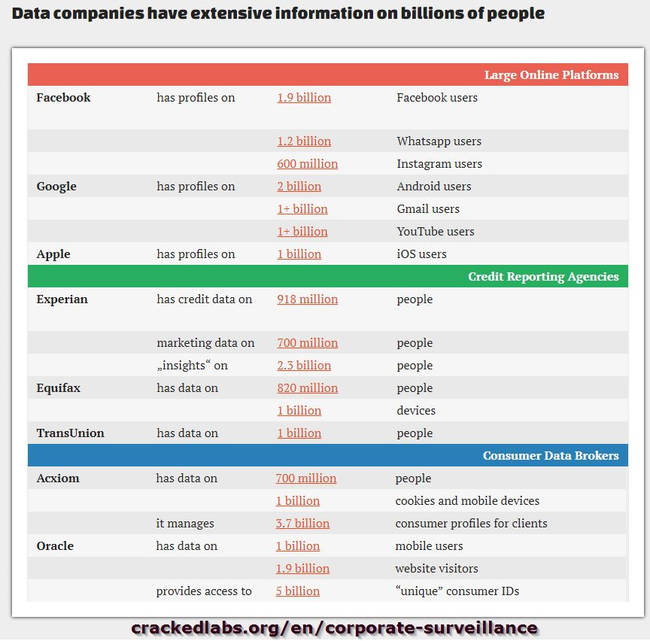
La datificazione e il controllo
In molti luoghi di lavoro, ma anche in alcune università (sicuramente molte americane), vengono assegnate delle tessere di identificazione che consentono di accedere, entro determinati orari, a determinati luoghi. La vita lavorativa viene quindi gestita da un algoritmo, ed è regolamentata tramite un software programmato da un ingegnere. Che in teoria potrebbe arbitrariamente abusare di tale possibilità. Questo algoritmo, queste “regole”, non si limitano a stabilire dove il dipendente o il professore, oppure lo studente, può andare e quando può andarci, ma regolamentano chi è un dipendente, un professore, o uno studente.
Con le tecnologie moderne il capitalismo ha fatto un enorme passo in avanti. Se una volta l’uomo era controllato perché rinchiuso in luoghi di controllo, come la fabbriche, ma anche le scuole, oggi l’individuo (individuo vuol dire indivisibile) può andare dappertutto, c’è decisamente maggiore libertà di movimento rispetto al passato. Ma il controllo non è scomparso, anzi oggi è ancora più pervasivo, tramite le telecamere, le tessere di identificazione, le smart car, i sensori immersi nelle strade e per le città. Tutti questi “sensori” che ci circondano scompongono l’individuo in una miriade di dati, che alimentano una enorme quantità di flussi di informazione che tramite mille rivoli (online, ma non solo) finiscono per riunirsi nei data base dei data broker a realizzare un profilo per ogni cittadino. L’individuo non è più, quindi, indivisibile, ma viene frammentato e ricomposto a creare quella che non è la banale transcodifica della sua vita in informazioni gestibili da un elaboratore, quanto piuttosto l’esercizio di un vero e proprio potere, una forma di controllo. È un algoritmo, una scatola chiusa che raccoglie input da mille fonti, li elabora secondo una specifica programmazione e fornisce degli output, a decidere chi è professore, chi è studente, anche chi è terrorista. Questa è la “datificazione”.
Leggi anche >> Rischi e problemi nella lotta al terrorismo nell’era degli algoritmi
Mentre le società del secolo scorso erano caratterizzate da un capitalismo di concentrazione, in luoghi di elezione come la fabbrica, le nuove società sono decentralizzate ed aperte. Il fulcro non è più la produzione, ma la distribuzione, e il marketing diventa strumento di controllo sociale. Alimentato dai Big Data che vengono raccolti, in maniera ben poco trasparente da centinaia di fonti, compreso il piccolo blog della piccola azienda.
Alcune polizze potrebbero essere limitate in base al luogo in cui si vive, le migliori condizioni di servizio essere offerte solo a determinate persone, un giornale potrebbe mostrare titoli diversi a seconda di chi legge, un prestito potrebbe essere rifiutato perché si hanno amici poveri sui social. Una persona appartenente ad una minoranza potrebbe essere discriminata non perché una banca gli rifiuta un prestito ma perché quell’offerta di credito non gli viene proprio fornita dall’algoritmo. Si può essere schedati quali appartenenti ad una banda semplicemente avendo molti conoscenti in comune (vedi articolo sul software PredPol utilizzato per la creazione di mappe del crimine).
Il GDPR mira a porre un freno ad una parte di questo, imponendo una trasparenza che consenta alle persone di essere consapevoli di ciò che succede alle loro vite e alle loro sfere personali, permettendo loro, dove possibile, di scegliere. Il GDPR, infatti, impone di informare gli interessati dell’esistenza di una decisione basata sul trattamento di dati automatizzato, e nell'informativa devono essere esplicitate le modalità e le finalità della profilazione, oltre che chiarire la logica inerente il trattamento e le conseguenze previste per l'interessato a seguito di tale tipo di trattamento.
La profilazione di per sé non è un male, ma occorre che sia trasparente, per impedire che una tecnologia possa sostituirsi alle nostre scelte e alla nostra libertà.
Immagine in anteprima via Pixabay




