

Tornano le proteste dei cittadini contro la direttiva copyright: in pericolo i nostri diritti
14 min letturaIl 26 agosto si terranno manifestazioni in tutta Europa , e anche in Italia a Siena, contro l’attuale testo della direttiva copyright (qui un articolo sulla proposta iniziale della Commissione europea) e in particolare contro l’articolo 13, ritenuto da molti esperti (per citarne solo alcuni: Tim Bernes Lee, il relatore speciale dell’ONU sulla libertà di espressione) pericoloso perché avrebbe un impatto negativo sulla libertà di espressione in rete.
In alternativa alla partecipazione alle manifestazioni puoi firmare la petizione su Change.org Stop the censorship-machinery! Save the Internet! (quasi 1 milione hanno già firmato)
Leggi anche >> >I danni che la direttiva sul copyright farà alle nostre libertà e cosa possiamo fare per contrastarla (dove riportiamo esperti ed organizzazioni che hanno criticato l’attuale testo della direttiva)
L’approdo delle proteste nel mondo fisico è ampiamente indicativo di quanto sia sentita la problematica in particolare dai cittadini. Questo accadde in passato anche contro ACTA, il trattato anticontraffazione che fu bocciato proprio grazie a massicce proteste dei cittadini in tutti gli Stati europei.
Opinioni in vendita?
In Italia, un paese nel quale le cronache quotidiane rivelano ogni giorno di più l’arroganza delle imprese private che hanno occupato tutti i settori e mostrano di non voler cedere di un solo millimetro, disinteressandosi dei diritti, delle libertà, e talvolta anche delle vite dei cittadini stessi, con la bocciatura di ACTA le associazioni di categoria sollevarono accuse nei confronti del legislatore europeo, reo di essersi fatto circuire da una diffusa disinformazione, fino al punto di recepire “istanze populistiche” (eravamo nel 2012), mostrando la sua incapacità di comprendere le dinamiche della rete. Si, avete letto bene, le aziende italiane che dicevano al Parlamento europeo di non capire nulla di Internet. Fate un raffronto tra lo stato della rete in Italia e quello negli altri paesi europei. Non serve altra risposta.
Oggi, come allora, girano accuse dello stesso stampo, rivolte direttamente alle associazioni per i diritti dei cittadini e in genere a coloro che, come Valigia Blu, cercano di spiegare la complessità di questo framework (quadro) normativo e i suoi pericoli. L’accusa è di essere circuiti dalle grandi aziende del web, Google e Facebook in primis.
Non ci sarebbe nemmeno bisogno di rispondere a stupidaggini del genere, ma corre l’obbligo di far osservare un paio di cose. Innanzitutto, quando leggete accuse di questo tipo in genere sono persone che lavorano per l’industria del copyright. Ma, soprattutto, è un modo per non ammettere la dignità di interlocutore all’avversario, un modo per delegittimare gli altri senza dover rispondere nel merito delle argomentazioni altrui.
Chi ascolta i cittadini?
Nel dibattito in corso, infatti, non si tratta di una contrapposizione tra industria del copyright (a proposito parte di questa industria è contraria alla direttiva copyright, pensate un po') e industria del web, si tratta, piuttosto, dei cittadini che, tramite le associazioni per i diritti civili (ce ne sono tantissime) e i mille rivoli di voci davvero indipendenti, come Valigia Blu (che risponde esclusivamente ai propri lettori), si sono prese carico di tutelare i loro stessi diritti, i diritti di coloro che spesso nemmeno gli stessi governi statali vogliono più tutelare. Laddove i governi spesso si interessano maggiormente di difendere gli interessi economici delle aziende. Dire che i cittadini sono circuìti dalle aziende del web, tra l’altro, vuol dire dare degli stupidi a quelli che, in teoria, dovrebbero essere gli stessi clienti dell’industria del copyright. L’industria del copyright continua a trattare i suoi stessi potenziali clienti come se fossero dei delinquenti, e per di più stupidi. Così come anni fa negli Usa si avviò una vera e propria caccia alle streghe criminalizzando un’intera generazione di ragazzi e non solo.
Volete un esempio? Nel 2006 Jamie Thomas viene citata negli Usa in giudizio da Capitol Records per aver scaricato illegalmente 24 canzoni per uso personale (non le vendeva, non le distribuiva). Un tribunale assegnò a Capitol Records un risarcimento di ben 222mila dollari, cioè 9250 dollari a canzone. In secondo grado il risarcimento salì fino a 1.920.000 dollari (80mila per brano) fino a tornare a 222.000 alla fine del giudizio. Il giudice tenne a ricordare che è l’importo massimo consentito dalla Costituzione. L’importo massimo!
Con l’approvazione della direttiva copyright con l’attuale testo, questo modo di fare dell’industria del copyright potrebbe diventare la regola anche in Europa. Con l’articolo 13 della direttiva, infatti, le grandi piattaforme del web, ma non solo quelle, dovranno introdurre dei sistemi di filtraggio dei contenuti immessi online per impedirne la pubblicazione se segnalati dall’industria del copyright. Cioè quei contenuti non saranno mai visibili, verranno cancellati prima che qualcuno li possa mai vedere. In breve, la decisione su ciò che è legale online sarà demandata ad accordi tra l’industria del copyright e le grandi piattaforme del web. E i diritti dei cittadini chi li tutelerà? Nessuno.
Leggi anche >> In nome del copyright si rischia la censura online affidata ad aziende private
A questo punto qualcuno potrebbe dire che comunque rimane il problema della pirateria. Ci sono però alcune considerazioni da fare a tal proposito. A parte che il discorso sulla pirateria andrebbe affrontato tenendo ben presente che molte delle forme professionali di pirateria non hanno assolutamente nulla a che fare con l'introduzione di filtri alle grandi piattaforme, come ad esempio la pirateria offline ma anche i cosiddetti OCH, o comunque i siti che sono dediti esclusivamente alla pirateria e che di certo non si trovano tramite Google Search, ma con link diretto distribuito da persona a persona. Per i quali siti occorrerebbe agire, piuttosto, sui finanziamenti, impedendo che i circuiti pubblicitari possano mettere i loro annunci su quelle piattaforme.
Il sistema principale dovrebbe essere, in realtà, quello di offrire contenuti legali in maniera semplice e a prezzi abbordabili, altrimenti si crea ovviamente un’offerta illegale che va incontro ad una ampia domanda di tali contenuti (per tanti anni l'industria del copyright si è semplicemente rifiutata di andare incontro alla domanda nascente, così determinando fenomeni di offerta illegale). Poi ci sono tante possibilità, quali ricorrere ad un giudice, casomai con provvedimenti di urgenza che in pochissimo tempo possono rimuovere contenuti.
Alcune aziende del web hanno introdotto volontariamente sistemi di segnalazioni successivi (non preventivi, in modo che sia possibile verificare quali sono effettivamente i contenuti tirati giù e se ci sono abusi) alla pubblicazione dei contenuti. Questi sistemi però difettano di procedure snelle per impugnare la rimozione e sanzioni pesanti per gli abusi di rimozione a carico di chi inoltra la richiesta. Un caso eclatante è quello di Stephanie Lenz che si vide rimuovere il video del proprio figlio che danza nella propria cucina sulle note di una canzone quasi inudibile. 10 anni ci ha messo per ottenere (parzialmente) giustizia. Chi mai potrebbe permettersi di combattere contro una multinazionale per così tanto tempo? L'industria del copyright si lamenta dei tempi della giustizia per tutelare i propri interessi. Beh, guarda caso, noi cittadini abbiamo lo stesso identico problema quando si tratta di tutelare i nostri diritti contro le multinazionali.
Leggi anche >> Il copyright, Napster, la cultura del Vietnam e l’Internet che verrà
Procedure soggette ad abusi
La mente subito corre a YouTube e Google, dove le rimozioni funzionano tramite algoritmi (ContentID per Youtube) che oscurano contenuti se segnalati dall'industria del copyright. I casi, purtroppo, nei quali si è verificato che gli algoritmi non funzionassero egregiamente, finendo per rimuovere contenuti che erano del tutto leciti, sono tantissimi, e crescono esponenzialmente.
Un caso piuttosto interessante che ci mostra come funzionano (male) gli algoritmi che dovrebbero presidiare il web è avvenuto proprio pochi giorni dopo il voto sulla direttiva copyright che si è tenuto a luglio. Quando il servizio Topple Track ha inviato una richiesta di rimozione a Google Search relativa a 23 link, ritenuti in violazione dei diritti d’autore di Gamble Breaux, una cantante australiana. Su 23 link ben 19 non violavano alcun copyright. Addirittura ben 6 link portavano a pagine o siti critici contro la direttiva copyright. Si chiedeva, ad esempio, la rimozione dell’intero sito savethelink che convoglia il materiale per la campagna di protesta contro la direttiva copyright. Un caso? Comunque il tasso di errore è significativo. Ovviamente da un caso singolo non si può ricavare una statistica significativa, ma raccolte di dati in materia esistono.
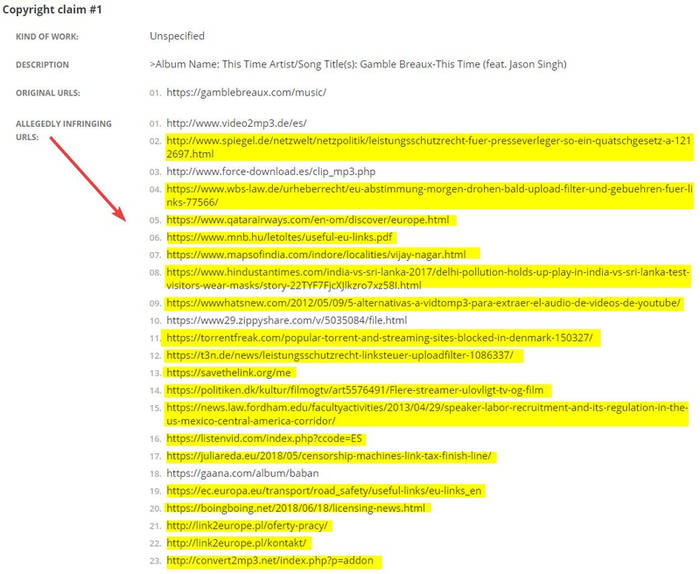
La stessa Google nel 2009 ammetteva che il 57% delle richieste di rimozione di contenuti viene da concorrenti (insomma le varie aziende titolari dei diritti si fanno la guerra online a spese dei diritti dei cittadini) e il 37% non sono valide richieste di rimozione. Sulla rivista online Techdirt sono documentati tantissimi casi nei quali le richieste di rimozione erano tentativi deliberati di mettere a tacere voci critiche o dissenzienti, o la stessa concorrenza. Si tratta di un perdurante abuso del processo di rimozione, che è sostanzialmente lo stesso processo che la direttiva copyright vorrebbe introdurre obbligatoriamente in Europa. Anzi peggio, perché il DMCA americano prevede che le richieste di rimozione avvengano dopo la pubblicazione del contenuto online, mentre l’articolo 13 della direttiva prevede che il controllo sia fatto prima della pubblicazione dei contenuti.
E dal 2009 ad oggi che è successo? Uno studio pubblicato dall'Università della California (Berkeley e Columbia University), dal titolo Notice and Takedown in Everyday Practice, ha rilevato che circa il 30% delle richieste di rimozione era discutibile (su un campione di 100 milioni di notifiche). La conclusione è che il sistema di rimozione è soggetto a numerosi abusi semplicemente perché conviene ed è sostanzialmente senza rischi.
Un rapporto di TorrentFreak del 2016 valuta che il sito 4shared, che conta 2 milioni di pagine, ha ricevuto oltre 50 milioni di richieste di rimozione (ogni richiesta è un url, quindi una pagina). È da notare che 4shared ha un proprio sistema di rimozione dei contenuti (tipo quello di Google) eppure i titolari dei diritti si rivolgono a Google Search. Considerato che la richiesta a Google rimuove la url dal motore di ricerca, ma il contenuto rimane online, mentre la richiesta a 4shared porta alla rimozione del contenuto vero e proprio, viene da chiedersi:
- perché rivolgersi a Google e non direttamente a 4shared?
Secondo il portavoce di 4shared è perché la maggior parte delle richieste di rimozione sono semplicemente false. Insomma ci sono dei bot che generano una quantità enorme di richieste di rimozione per url del tutto inesistenti oppure utilizzando termini del tutto generici (tipo “video”). Questo è il risultato dell’utilizzo di strumenti automatizzati, come i famosi algoritmi (o filtri) che la direttiva copyright vorrebbe introdurre.
Un report di TorrentFreak del 2017 identifica decine di milioni di false notifiche di rimozione DMCA inviate a Google su un sito web praticamente senza traffico. mp3toys.xyz riceve in pochi mesi oltre 49 milioni di richieste di rimozione, moltissime del tutto inventate da una società antipirateria.
Gonfiare il fenomeno
Eppure tutto questo non è niente a fronte dei dati estrapolabili dai rapporti diretti di Google sul suo programma di rimozione. Nel rapporto del 2017, ad esempio, si legge che una parte significativa dell’aumento di volume delle richieste di rimozioni dipende da comunicazioni che sembrano duplicate, non necessarie o errate. Un numero considerevole di richieste di rimozione inviate a Google riguardano URL che non sono mai state nell’indice di ricerca e che pertanto non avrebbero mai potuto essere visualizzate nei risultati di ricerca. Ad esempio, a gennaio 2017, il mittente più prolifico segnala 16.457.433 URL nel motore di Google, ma a seguito di un'ulteriore ispezione, 16.450.129 (99,97%) di quegli URL non erano nell’indice di Google. In totale, secondo Google, il 99,95% di tutti gli URL elaborati dal Programma di rimozione dei diritti d'autore attendibili a gennaio 2017 non erano inclusi nell’indice di Google. Le richieste erano false.

Sempre nel rapporto si evidenza che molte delle richieste sembrerebbero generate semplicemente rimescolando le parole in una query di ricerca e aggiungendole a un URL, in modo che ogni query si riferisca ad un URL diverso che comunque porta alla stessa pagina di risultati.
Che senso ha aumentare artificialmente il numero di richieste di rimozione? Questa massiccia mole di richieste di rimozione di contenuti illeciti (inesistenti) ha un effetto mediatico enorme. Sono, infatti, questi i dati sbandierati a più riprese dall’industria del copyright per supportare le sue richieste di tutele rafforzate, di nuove e più draconiane leggi a difesa dei loro interessi economici. E sono questi i dati che fungono da supporto alla campagna dell'industria a favore della direttiva copyright: il web trabocca di contenuti pirati. Solo che non è vero.
Un momento, però. Google dice, Google precisa, Google afferma. Non sarà che utilizziamo dati di Google che casomai ci marcia? In effetti è vero che Google finanzia numerosi progetti, e studi come quello dell’Università della California sono in parte finanziati anche da Google (per un terzo nel caso specifico). A chi credere?
È ovvio che le industrie tirano l’acqua ai loro mulini, tutte, e quindi evidenziano i dati che gli interessano. Comunque l’equazione alla fine è sempre quella, Google dice, l’industria del copyright dice. Il problema, però, non è stabilire chi ha ragione tra le aziende tech e l’industria del copyright, essendo entrambe interessate ai loro affari, e si fanno la guerra tra loro (e in qualche caso usano anche mezzi non troppo leciti, basta considerare il cosiddetto progetto Goliath, un esempio di pressione su un procuratore statale per avviare azioni legali contro Google su basi inesistenti). Il punto è che nessuno ascolta realmente cosa dicono i cittadini. Nessuno tutela i loro diritti.
Gli abusi cancellano opinioni
E allora torniamo al caso di Topple Track, che invia una richiesta di takedown nella quale si chiedeva la rimozione dall’indice di ricerca di Google di ben 6 articoli o siti che parlavano diffusamente della direttiva copyright criticandola. È possibile che sia solo un caso, un errore? Cioè, chiedetevi, è possibile che un sistema automatizzato abbia commesso tanti errori (19 su 23) e guarda caso per lo più in una specifica direzione? Il punto è che, errore o meno, l’algoritmo non ha funzionato in quel caso, ha chiesto la rimozione di contenuti che per alcuni giorni non erano davvero rintracciabili sul motore di ricerca. Vi diranno di no perché attualmente quelle pagine sono state ripristinate nell'indice del motore di ricerca, ma ha ammesso la stessa azienda che ha inviato le richieste, come riportato da EFF:
Symphonic Distribution (which runs Topple Track) contacted EFF to apologize for the improper takedown notices.
Improper takedown notices.
In questo modo si è sottratto al dibattito pubblico una parte delle opinioni. Quelle dei cittadini, quelle per i cittadini. Non le opinioni di e per l’industria del copyright né quelle di e per l’industria del web. Errore dell'algoritmo o peggio, si tratta di una palese ed evidente violazione della libertà di manifestazione del pensiero che, in un paese democratico, dove la voce dei cittadini deve contare e tutti devono partecipare al dibattito democratico, non è semplicemente accettabile. Non è accettabile. Non importa se poi non ci sono prove statistiche diffuse o non sono attendibili perché lo studio è parzialmente pagato da Google (e quanti sono gli studi pagati dall'industria del copyright?). Ci sono casi, tanti casi (alcuni li riporto qui) nei quali la voce dei cittadini è stata silenziata. Ci sono tanti casi che riporta Techdirt, e tanti altri siti, compreso EFF che ha un’apposita pagina con la Hall of Shame del copyright. Nel 2011 Warner viene citata in giudizio ed è costretta ad ammettere di aver chiesto ed ottenuto la rimozione di contenuti che non solo non erano di sua titolarità, ma addirittura non erano nemmeno illeciti, compreso titoli di pubblico dominio ed un software open source. E se non vi bastano potete cercare su un motore di ricerca “bogus+takedown”. Il problema è davvero conoscere l'esatta percentuale di abusi?
Sono talmente tanti gli abusi che nel 2014 l’R Street Institute, un think tank specializzato in ricerche politiche, pubblica un'interessatissimo studio dal titolo “Guarding against abuse: Restoring constitutional copyright”. Uno studio che segue, ideologicamente, quello scritto per conto della Commissione Studi dei Repubblicani della Camera degli USA, che sosteneva che oggi il copyright non ha più lo scopo di compensare l'autore per il suo sforzo creativo, quanto piuttosto la funzione di massimizzare i profitti delle aziende all'interno di un regime di monopolio imposto dal governo stesso. Insomma, il copyright non serve a tutelare gli artisti, ma solo a far guadagnare più soldi alle aziende. Lo studio provocò forti proteste da parte delle lobby al punto che venne rimosso dal sito della Commissione Studi dopo appena 24 ore, e l'autore fu licenziato. Il metodo è quello: silenziare il dissenso.
Il punto, allora, è che i cittadini non sono le aziende del web e non sono l’industria del copyright, i cittadini hanno una voce e delle opinioni del tutto separate e autonome, e sopratutto hanno dei diritti, molti di essi considerati diritti fondamentali, cosa che invece le aziende non hanno. Queste hanno interessi economici. Facciamo che si combattano tra loro accusandosi di chi paga chi. E' il loro metodo, è la loro mentalità, è il loro modo di vedere le cose, credere che le opinioni siano in vendita al maggior offerente. Noi cittadini teniamoci da parte, tutelando autonomamente i nostri diritti. Non si tratta di fare un Internet a misura dell’industria del copyright né a misura delle aziende tech, ma un Internet a misura di essere umano.
Intellectual property rights are not human rights, Farida Shaheed, relatore speciale dell'ONU sui diritti culturali
Tre framework normativi
E se guardiamo la rete Internet nell’ottica dei diritti umani, allora la questione cambia completamente. È vero, ed è indubitabile, che vi sia un problema di pirateria. Come del resto c’è un problema di reati nella realtà fisica, oppure di incidenti sulle strade. Per risolvere il problema degli incidenti non si potrebbe, ad esempio, vietare tutte le auto? Oppure fare in modo che soggetti esterni (il produttore?) controllino tutte le auto e decidano quando possono partire, dove devono andare e cosa devono fare? Per ridurre considerevolmente i reati non basterebbe impiantare un chip all’interno del corpo di ognuno di noi che ci controlla costantemente? Il problema è la proporzionalità delle soluzioni implementate. Il bilanciamento con gli altri diritti.
Allora, immaginate il framework normativo in materia di copyright come se fosse un quadro, appeso ad una parete bianca. Qui è li vediamo delle macchie scure che sono la pirateria, e vedendo quel quadro, e volendo risolvere il problema della pirateria, appare ovvio applicare una soluzione drastica: rimozioni, filtri. Ma poi ci sono altri due quadri che dobbiamo considerare, il framework normativo in materia di protezione dei dati personali, che è importante, perché rimuovere, poi consentire eventualmente la possibilità di impugnare la rimozione, casomai anche procedure stragiudiziali e giudiziali, comporta il trattamento di numerosi dati personali. Ed infine un altro, forse il più importante quadro, costituito dalle norme a tutela dei diritti fondamentali del cittadino, come la libertà di manifestazione del pensiero che è alla base di qualsiasi Stato democratico.
Se introduciamo una modifica nel framework copyright, non possiamo prescindere da una valutazione di impatto di questa modifica sugli altri due framework. Se l’aumento della tutela (enforcement) dell’industria del copyright (ricordiamo che si tratta di tutelare dei meri interessi economici non dei diritti fondamentali) implica una compressione maggiore dei diritti degli altri framework non si può prescindere da una valutazione esaustiva della proporzionalità della misura nuova introdotta, appunto l’impatto sugli altri diritti. Ecco dove sta, alla fine, il vero problema. Pensiamo a questo, mentre le industrie si interrogano chi paga chi chiudendosi nelle loro torri d'avorio e sognando un mondo dove tutto è in vendita, compreso le libertà.
Se aumentare la tutela del copyright comporta dover accettare che il tuo discorso, il tuo articolo, il tuo sito che contribuisce al dibattito pubblico sull’opportunità di una legge, ma potrebbe trattarsi di qualsiasi altra cosa, deve poter essere cancellato da una decisione presa in un accordo tra l’industria del copyright e l'industria del web, allora c’è qualcosa che non funziona. Ecco perché l’attuale testo della direttiva copyright non va bene. E' la commistione di interessi tra le aziende del web e l'industria del copyright a realizzare un'inaccettabile compressione dei diritti fondamentali dei cittadini.
Leggi anche >> La libertà di espressione nell’era dei social network
E per la pirateria, allora che facciamo? Non ci sono evidenze che la pirateria danneggi l'industria. Ma lo dice Google? No, lo dice uno studio della Commissione europea, che però non voleva pubblicare. Chissà perché.
In general, the results do not show robust statistical evidence of displacement of sales by online copyright infringements. That does not necessarily mean that piracy has no effect but only that the statistical analysis does not prove with sufficient reliability that there is an effect.
Leggi anche >> I danni che la direttiva sul copyright farà alle nostre libertà e cosa possiamo fare per contrastarla (dove si spiega anche che se una riforma della normativa copyright è da realizzare questa riforma è pericolosa).
Foto anteprima via Pixabay




